互联网时代产生了海量的舆情数据,借助于这些海量的数据信息刻画社会系统的运行逻辑与社会结构的特征,是计算社会科学的一个重要研究方向。借助于社会学的“结构叙事”,龚为纲及其研究团队最近2年先后根据舆情大数据GDELT的海量信息,开展了2项“结构社会学”的相关研究,分析结果先后刊发于《政治学研究》(2018年第4期)和《社会学研究》(2019年第5期),前者试图借助于GDELT数据库,刻画中国社会各阶层的情绪体验以及不同阶层之间的互动关系,并据此透视当代中国社会的阶层关系;后者则试图从世界体系的角度,刻画全球社会的媒介信息传播结构,据此透视“文化帝国主义”与世界体系的结构逻辑。
据悉,这两项研究的数据来源为GDELT数据库,GDELT(“全球事件,语言和语调数据库”)是世界上最大的政治事件开放数据库,其信息来源于全球100多个国家、65种语言中的社交媒体、门户网站、网络论坛、网络新闻信息,其中2015年2月-2019年9月,该数据库已经汇聚了全球各种新媒体平台上大致10亿张网页的信息,数据体量高达10TB。该数据库由谷歌开发者 Kalev Leetaru根据 Philip A. Schrodt 和其他人在2011年的工作开发而来。自2014年以来,可以在 Google BigQuery 网络界面查询,龚为纲等主要通过Google Bigquery云计算平台对GDELT数据进行处理。
这两项研究的主要数据源主要包括GDELT数据的两种形式。第一种是根据GDELT数据库所提供的半结构化信息,相关数据目前存储在Google Bigquery平台上。Kalev Leetaru等人将全球舆情大数据汇集起来之后,由于受版权限制,他们并不能在谷歌云平台上直接公布这些数据库的原始文本形态,只能向用户提供经过各种算法(主要是主题模型算法和情感词库技术)所提取的半结构化信息,这些半结构化信息包含很多丰富的内容,本研究的媒介议题分析(Themes)、媒介语调(Tone)分析、超链接网络分析等都来源于这部分信息。但这些半结构化数据是经过算法处理之后的二手数据,由于缺乏原始文本数据,所以无法对媒介话语的内容展开分析,这样就必须涉及到本研究的第二部分数据信息。第二种是根据GDELT数据库所提供的网页URL信息,进行定向网络爬虫,进而获取本研究所需要的3.5亿篇英文文本的原始信息,用于分析发达国家涉华舆情的话语建构特征。通过安畅云部署了100多台服务器,借助于通用网络爬虫程序将2015-2018年间所有来自西方发达国家和部分英语国家中的英文文本信息全部爬取下来,这大致涉及到3.5亿篇英文文本信息,对西方国家的政治话语分析以及内容分析主要来源于这部分数据。
附录:
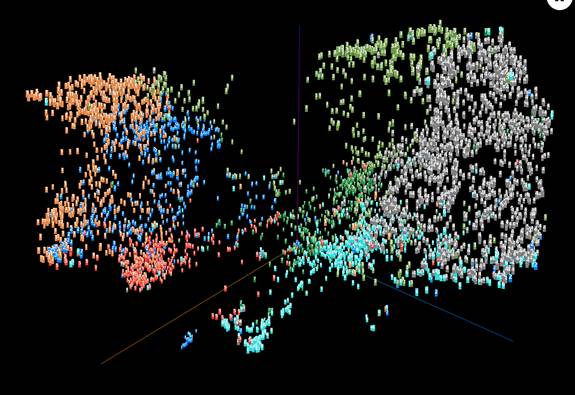
《社会学研究》原文插图(1):中国威胁论的话语空间:基于句向量算法
注释:借助于谷歌云在AI Hub中最近推出的通用句子编码系统(Universal Sentence Encoding,下面简称USE),我们对新闻文本中有关“中国威胁论”的文本进行语义编码,借助于这一算法,将句子和段落等非结构化的文本语义信息结构化为512维向量。语料库中共有58472句直接与中国威胁有关的语料(图中每一个点代表一句话对对应的向量),借助于USE将每一句与中国威胁有关的语料转化成为512维向量,然后对这个58472×512的数组调入到Google Bigquery平台中,借助于K-Meams算法,以512维向量为运算对象,对上述数组进行分类,并将分类结果纳入到谷歌云的Tensorboard Projector中进行可视化。结合K-means算法和Tensorboard Projector的可视化结果,去掉向量空间中那些明显与中国威胁论在语义上无关的奇异点,中国威胁论的话语空间及其语义结构如上图,在上图的话语空间结构中,语义集群1、2、5分别表示经济威胁、贸易威胁和科技威胁,由于经济威胁(第1类)和贸易威胁(第2类)、科技威胁(第5类)密切关联,所以我们看到语义空间结构中第1类分别和第2类与第5类在语义上密切关联;语义集群3、4、6、7则主要是中国军事威胁,第4类主要是在炒作中国军事实力和尖端武器的发展对美国所构成的军事威胁,而3、6、7则分别在炒作中国在东北亚(日本与韩国)、东南亚(南海)和南亚对美国亚太盟友所造成的军事威胁,由于这4个语义集群都是在炒作中国军事和安全威胁,所以它们在向量空间中密切关联,中国军事威胁话语非常侧重于炒作中国崛起对周边国家的威胁。
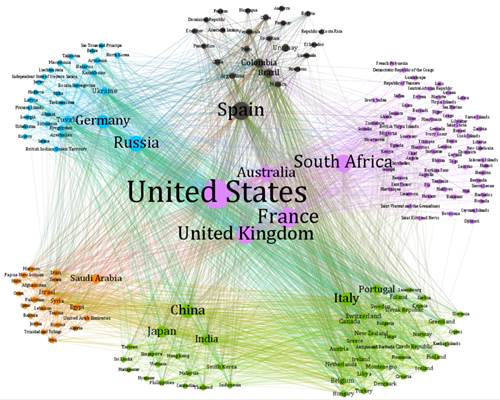
《社会学研究》原文插图(2):网络超链接所展示的全球媒介信息互动结构
注释:基于全球新媒体语料库中18亿个超链接,展示国家之间的媒介互动关系。这张图显示的是各国媒介超链接互动的网络结构,每一个节点代表一个国家,节点越大,代表与其他国家建立的链接数量越多,这些国家在全球舆情空间中的话语权越大。节点与节点之间根据超链接互动数量形成边。节点之间因为联系密切,形成各种各样的凝聚子群和圈群结构,通过社区探索算法,我们一共识别出六个文化圈群,圈群内部超链接互动关系更加紧密。
通过这张网络关系图,我们可以清晰地呈现当前新媒体中的媒介信息传播网络,既能从中看到经典的媒介帝国主义理论中“核心-边缘”机制所提供的洞见,也能从中看到基于地理区域、共同语言和历史文化的 “文化圈群”(即网络结构中的“凝聚子群”)。也就是说,当前全球新媒体互动所展示的全球传播秩序,既在很大程度上延续了过去的“核心-边缘”机制,同时也展示了共同语言和历史文化等因素在塑造媒介传播景观方面的重要意义。除此之外,图6也刻画了不同圈群内部以及圈群之间的媒介互动关系,这实际上是当今世界主要文明之间,在信息共享、经济文化上的交流网络,表达了文明内部的亲缘关系以及文明之间的边界。



